SRE / DevOps / Kubernetes Weekly Reportまとめ#45(12/6~12/11)
- この記事は2020/12/6~12/11発行の下記3つのWeekly Reportを読み、備忘録兼リンク集として残しているものです。
- なるべく情報を早く届けたい/共有したいので、ブログのリンクを確認次第、先行公開しています。自身のコメントは随時追加しています。
- English Version of this blog is here.
- DEVOPS WEEKLY ISSUE #519 December 6th, 2020
- News
- A post on moving from systems administration to information security, with good observations of the advantage of being new to a topic and how a variety of skills help when moving to different roles.
- Hindsight is an interesting design tool for future systems. This post, from someone ver familiar with its working, looks at what applying hindsight and some opinions to Kubernetes might mean if you build a new container orchestrator.
- An interesting post on scaling CI/CD pipelines across development teams, with a focus on self-service.
- A breakdown of the recent large AWS outage, based on the public information but with a useful diagram to understand the apparent architecture and a handy list of the proposed plans to avoid similar issues in the future.
- Software is always rooted in when it was first written. This post touches on GitHub’s architecture and technology choices and also how, and why, that’s evolving.
- Details of scaling datastores, from active/active MySQL clusters to using Vitess.
- The Kubernetes API is designed to be extended with new resources. This post looks at a more flexible Deployment resource which supports more fine grained control around rollout and running multiple versions of a service at the same time.
- Tools
- Opstrace is a new horizontally-scalable metrics and logs platform, optimised for installation on cloud platforms. It exposes a prometheus-compatible API, as well as working with a variety of agents like those from Fluentd and Datadog.
- Replicate is a new tool that aims to solve version control problems for machine learning. It’s a python library that allows for snapshots to be saved in S3 or Google Cloud Storage and tools for retrieving and reusing those versions.
- Nydus is a set of tools that aims to improve over the current OCI image specification in terms of container launching speed, image space and network bandwidth efficiency. The tutorial is a nice way of understanding how it works.
- News
- SRE Weekly Issue #247 December 6th, 2020
- Articles
- 2020 09 25 Incident: Infrastructure connectivity issue impacting multiple systems
- Google Cloud Issue Summary — Google Drive — 2020-11-16
- What I Wish I Knew About Incident Management
- Scaling Datastores at Slack with Vitess
- Mitigate Connection Leaks in Production via Proxies
- Improving the Resiliency of Our Infrastructure DNS Zone
- Root Cause Analysis For Reliability: A Case Study
- Outages
- Articles
- KubeWeekly #243 December 11th, 2020
- The Headlines
- ICYMI: CNCF Webinars
- CNCF Member webinar: Fundamentals of OpenTelemetry
- CNCF Member webinar: A look at how Hackers exploit Prometheus, Grafana, Fluentd, Jaeger & more (hacking monitoring for fun and profit)
- CNCF Member webinar: Preventing Kubernetes misconfiguration: static analysis and beyond
- CNCF Member webinar: SPIFFE and SPIRE in practice
- CNCF Member webinar: Metal³: Kubernetes-native bare metal host management
- The Technical
- Using Snyk and Podman to scan container images from development to deployment
- Kubernetes: Efficient multi-zone networking with topology aware routing
- OpenShift/Kubernetes failure stories at scale - Lessons learned from large and dense deployments
- Automating volume expansion management - an operator-based approach
- OPA the easy way feat. Styra DAS!
- How to use a policy engine to improve your security posture
- Service discovery in Kubernetes - combining the best of two worlds
- Kernel privilege escalation: how Kubernetes container isolation impacts privilege escalation attacks
- GSoD 2020: Improving the API reference experience
- The Editorial
- Upcoming CNCF webinars
この記事は2020/12/6~12/11発行の下記3つのWeekly Reportを読み、備忘録兼リンク集として残しているものです。
なるべく情報を早く届けたい/共有したいので、ブログのリンクを確認次第、先行公開しています。自身のコメントは随時追加しています。
- 誰かの情報源や検索工数削減などになれば幸いです。
DEVOPS WEEKLY ISSUE #519 December 6th, 2020
SRE Weekly Issue #247 December 6th, 2020
KubeWeekly #243 December 11th, 2020
English Version of this blog is here.
- この記事を読んで疑問点や不明点があれば、URLから本文をご確認の上、ご指摘頂ければ幸いです。
- 理解が浅いジャンルも、とにかくコメントする様にしていますので、私の勘違いや説明不足による誤解も多々あろうかと思います。
- 情報量が多いので文字とリンクだけに絞っております。
- 各レポートで取り上げられている記事には2019年以前のものもあり、必ずしも最新のものという訳ではない様です。
DEVOPS WEEKLY ISSUE #519 December 6th, 2020
News
A post on moving from systems administration to information security, with good observations of the advantage of being new to a topic and how a variety of skills help when moving to different roles.
- タイトルは「A SYSADMIN MOVES TO INFOSEC」。
- 筆者がシステム管理者とソフトウェア開発者をしばらく務めた後、infosecチームに参加した方法について解説し、同様の経験を持っている方に、情報セキュリティーをオススメしている。
- 筆者のようなロールの変更が合っているかを自問する下記4つの投げ掛けがある。
- DO YOU LIKE INVESTIGATING AND TROUBLESHOOTING?
- DO YOU LIKE LEARNING?
- MAYBE YOU LIKE MAKING CONTENT AND GIVING PRESENTATIONS AND TRAINING?
- DO YOU LIKE TECHNICAL WRITING?
Hindsight is an interesting design tool for future systems. This post, from someone ver familiar with its working, looks at what applying hindsight and some opinions to Kubernetes might mean if you build a new container orchestrator.
- タイトルは「A better Kubernetes, from the ground up」。
- 筆者がApple社Senior Site Reliability EngineerであるVallery Lancey氏とチャットして刺激を受け、Kubernetesを互換性は考慮せずにゼロから作り上げる場合に、何がポイントでどこを変えるかを解説している。
- 以下の項目に沿って解説している大作。
- Guiding principles
- Mutable pods
- Version control all the things
- Replace Deployment with PinnedDeployment
- Explicit orchestration workflows
- Explicit field ownership
- IPv6 only, mostly
- … Or just don’t
- Security is yes
- gVisor? Firecracker?
- Very distributed clusters
- VMs as primitives
- How to storage?
- The end
An interesting post on scaling CI/CD pipelines across development teams, with a focus on self-service.
- タイトルは「How to Build a CI/CD Process That Deploys on Kubernetes and Focuses on Developer Independence」。
- 先週のKubeWeeklyで取り上げたので割愛します。
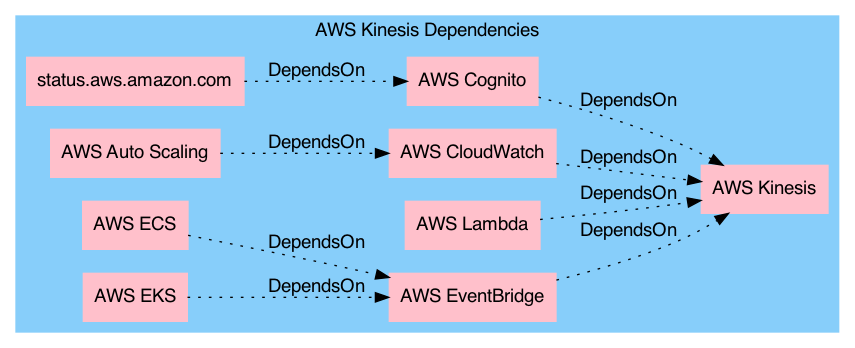
A breakdown of the recent large AWS outage, based on the public information but with a useful diagram to understand the apparent architecture and a handy list of the proposed plans to avoid similar issues in the future.
- タイトルは「Kinesis Outage」。
- 以前取り上げているAWSのKinesisに端を発した障害のサマリーを筆者が読み、Donella Meadows氏の「Systems Thinking in Practice」を読んで考えをまとめたページをふりかえり、関係するポイントをリンクしながら解説している。
- Kinesisと他のサービスのDependencyは下記の概略図を参考に。
Software is always rooted in when it was first written. This post touches on GitHub’s architecture and technology choices and also how, and why, that’s evolving.
- タイトルは「GitHub's journey towards microservices and more: 'We actually have our own version of Ruby that we maintain'」。
- GitHub社のVP of Software EngineeringのSha Ma氏にQCon Plus virtual developer eventでインタビューしている記事。
- 以下の質疑は2018年にMicrosoft社にM&Aされてからの動きとして、個人的に気になっていた部分。
- GitHub was largely hosted on its own data centres. Is that moving to Azure?
- "We're exploring things potentially to move," Ma said. "We actually still have things hosted on AWS. For example, a lot of our data analytics is on AWS and we've started a project to look at migration into Azure, especially since we get internal pricing which is more favourable for us. But a large part, I would say 80-90 per cent of our stuff is hosted in data centres that we physically maintain."
- GitHub was largely hosted on its own data centres. Is that moving to Azure?
- 以下結論部分はマイクロサービスとモノリスのアーキテクチャーの議論の核心部分と思い、抜粋。
- タイトルにあるRubyと、MySQLについては社内に強いエキスパートがいるので、引き続き利用していく方向とのこと。パフォーマンスがクリティカルなコードはGolangでモノリスの外で書いているとのこと。
- "Microservices is not your solution to technical debt and bad architecture," Ma told us. "I think there's been a trend of people who went down the microservices path and are now going back into monolith because microservices became too unwieldy for them. Microservices doesn't replace good architecture. Going through things like, what should be grouped together? How should we look for things that cross domain boundaries? How should we set up teams and on-call? pushed us towards better architectural practices that benefit us both in the monolithic and microservice world. A lot of the preparatory work we're doing, we're actually doing in the monolith before extracting it."
Details of scaling datastores, from active/active MySQL clusters to using Vitess.
- タイトルは「Scaling datastores at Slack with Vitess」。
- 先週のKubeWeeklyで取り上げたので割愛します。
The Kubernetes API is designed to be extended with new resources. This post looks at a more flexible Deployment resource which supports more fine grained control around rollout and running multiple versions of a service at the same time.
- タイトルは「Introducing Kubernetes PinnedDeployments」。
- v1alpha1のAPIグループ「PinnedDeployment Kubernetes CRD」のプロジェクトで活動している筆者がタイトル通り紹介している。興味深い機能でフィードバックを募集されているそうなので、コメントされたい方は筆者まで返すと良さそうです。ラフな部分が丸められたらベータAPIにアップグレードされるとのことです。
Tools
Opstrace is a new horizontally-scalable metrics and logs platform, optimised for installation on cloud platforms. It exposes a prometheus-compatible API, as well as working with a variety of agents like those from Fluentd and Datadog.
- 上記の通り水平方向にスケーラブルなメトリックとログのプラットフォーム 「opstrace 」のGitHubページ。
- オープンAPIと大規模なサービスプロバイダーのシンプルなユーザーエクスペリエンスを組み合わせて、安全で水平方向にスケーラブルなオープンソースの可観測性を、独自のクラウドアカウントにデプロイする。
Replicate is a new tool that aims to solve version control problems for machine learning. It’s a python library that allows for snapshots to be saved in S3 or Google Cloud Storage and tools for retrieving and reusing those versions.
- 機械学習用のバージョンコントロール用のツール「Replicate」のWebページ。
- GitHubページはこちら。
Nydus is a set of tools that aims to improve over the current OCI image specification in terms of container launching speed, image space and network bandwidth efficiency. The tutorial is a nice way of understanding how it works.
- 現在のOCIイメージ仕様を改善するコンテナーイメージ形式の上にユーザースペースファイルシステムを実装するプロジェクト「Nydus」のGitHubページ。
SRE Weekly Issue #247 December 6th, 2020
Articles
2020 09 25 Incident: Infrastructure connectivity issue impacting multiple systems
This incident report from a September Datadog outage has an interesting tidbit aboiut scaling external incident response in tandem with internal.
Alexis Lê-Quôc — Datadog
- 2020/10/06付けの記事。September 24, 2020, 14:27 UTC ~ September 25 00:40 UTCに発生したDatadog社のUSリージョンでの障害についての同社のレポート。
Google Cloud Issue Summary — Google Drive — 2020-11-16
This is Google’s write-up for an interesting issue that involved repeated re-sending of invitations to edit a Google Drive document.
- EditorのコメントにあるようにGoogle Driveの共有WebUIを使用して「プロファイルのメールアドレスに大文字が含まれているユーザーまたはグループ」とDriveのリソースを共有する際に送信される、最初の通知メールが繰り返し重複していた。
What I Wish I Knew About Incident Management
I basically want to immediately absorb any article with this title, unless it’s just clickbait spam. This one definitely isn’t.
Ronak Nathani
- 筆者がLinkedin社のSREとして長年にわたって習得したインシデント管理のプラクティスを共有している。
- テーマになっているオンコール対応に限らず、アラート対応の参考になる。
- 記事中に「Linuxや分散システムのデバッグは含まないので、最前線の話はSoftware Misadventures Podcast!で」と案内があり。確認してみたら、#1でゲストにKelsey Hightower氏を迎えていた。
Scaling Datastores at Slack with Vitess
Lots of juicy details in this one about the difficulty Slack has had in scaling their DB layer and how Vitess solved their problems.
Arka Ganguli, Guido Iaquinti, Maggie Zhou, and Rafael Chacón — Slack
- 先週のKubeWeeklyで取り上げたので割愛します。
Mitigate Connection Leaks in Production via Proxies
Hitting file descriptor limits is such an annoying kind of outage. Some good tips here, clearly coming from hard-won experience.
Utsav Shah
- Connection Leaksを軽減するために連携して使用できるいくつかのアプローチと、それぞれのトレードオフを解説している。
- Singletons/Dependency Injection
- Client Count Metrics
- File Descriptor Count Alerts
- Sidecar Processes
Improving the Resiliency of Our Infrastructure DNS Zone
They used two providers synced with OctoDNS.
Ryan Timken and Kiran Naidoo — Cloudflare
- 複数のプライマリネームサーバーを使用して、エッジで実行されている独自のDNS製品とサードパーティのDNSプロバイダーを活用することで、インフラのDNSゾーンの信頼性を高める方法を解説している。
- 独立かつ同時に複数プロバイダーのゾーンを管理するためOctoDNS を採用している。
Root Cause Analysis For Reliability: A Case Study
This is all about understanding the whole system (people and technology) and building learning, rather than finding a superficial “root cause”.
Piyush Verma — Last9
- 「なぜ信頼性のためにRCA(Root Cause Analysis)が必要か?」から、筆者の経験に基づいてタイトルの内容の解説に入っている。
Outages
- Solana
- Poloniex
- New Zealand Reserve Bank
- OneDayOnly
Local e-commerce site OneDayOnly is running Black Friday discount deals again today, after the shopping site was down for a few hours last Friday.
- Infura
- MobileCause
This outage occurred on Giving Tuesday, a very important day for nonprofits to raise funds.
上記各社の障害情報
KubeWeekly #243 December 11th, 2020
The Headlines
Editor’s pick of the highlights from the past week.
Kubernetes 1.20: The Raddest Release
Kubernetes 1.20 Release Team
The final Kubernetes release of 2020 is "the raddest release", bringing 42 enhancements to the project as well as bug fixes and performance improvements. Check out the release notes or listen to the Kubernetes Podcast interview with the release team lead Jeremy Rickard.
- Kubernetes.ioのKubernetes Blogからタイトル名の記事。Kubernetes 1.20の下記概要と「Major Themes/Major Changes/Other Updates/Release notes/Availability of release/Release Team/Release Logo/User Highlights/Project Velocity/Ecosystem Updates/Event Updates/Upcoming release webinar/Get Involved」の項目ごとに解説、関連情報をリンクしている。
- 42 enhancements: 11 enhancements have graduated to stable, 15 enhancements are moving to beta, and 16 enhancements are entering alpha.
- Google社社員によるKubernetes Podcastの「#131 Kubernetes 1.20, with Jeremy Rickard」も関連でリンクされている。
- News of the weekで気になったトピックは以下の通り。AWS re:Invent関連はこの場では割愛、個人的には全てチェックしています。
- 以下ネコの写真はKubernetes 1.20の「Release Logo」。

ICYMI: CNCF Webinars
You can view all CNCF recorded and upcoming webinars here.
CNCF Member webinar: Fundamentals of OpenTelemetry
Ted Young, Director of Developer Education @Lightstep
- OpenTelemetryを使い始めるために知っておくべきことのすべての説明を試みている。
CNCF Member webinar: A look at how Hackers exploit Prometheus, Grafana, Fluentd, Jaeger & more (hacking monitoring for fun and profit)
Omer Levi Hevroni, Application Security Engineer @Synk
- タイトルにあるツール(Prometheus, Grafana, Fluentd, Jaeger & more)の脅威モデリングを実施し、それらがどのようなリスクをもたらすかをチェックしている。
- 監視インフラをより適切に保護する方法についてのいくつかのアイデアと、独自のシステムの脅威モデリングを実行する方法の理解が深められる。
CNCF Member webinar: Preventing Kubernetes misconfiguration: static analysis and beyond
Matt Johnson, Developer Advocate Lead @Bridgecrew
- 実行時にCI / CDクラスターとKubernetesクラスターの両方でpolicy-as-codeを使用して、インフラを大規模に作成、テスト、維持するためのベストプラクティスを以下のポイントで解説している。
- Compare methods for securing infrastructure using open-source tools including Checkov
- Review sample use cases that showcase the benefits of different approaches
- Cover the current state of open source repositories and Kubernetes manifests found in the wild
CNCF Member webinar: SPIFFE and SPIRE in practice
Dan Feldman, Principal Software Engineer @Hewlett Packard Enterprise Umair Khan, Product Marketing Lead @Hewlett Packard Enterprise
- 2つのプロジェクト(SPIFFE and SPIRE)の主要なユースケースを紹介し、世界で最も大きく、最もセキュリティを意識している組織のいくつかで安全なシステムの構築に、それらがどのように使用されるかを探っている。
- SPIFFEとSPIREがニーズに適しているかどうか、およびそれらを使用して組織のセキュリティー体制を改善する方法を学べる。
CNCF Member webinar: Metal³: Kubernetes-native bare metal host management
Maël Kimmerlin, Senior Software Engineer @Ericsson Software Technology Feruzjon Muyassarov, Experienced Developer @Ericsson Software Technology Pep Turro Mauri, Senior Software Engineer @Red Hat
- Metal³(metalkubedと読む模様)プロジェクトとその動機を紹介し、これまでに達成してきたことの概要を説明している。
kubernetes.us10.list-manage.comJust a few days left to submit your #KubeCon + #CloudNativeCon EU proposals!@karenhchu and @bridgetkromhout have some great advice for you on putting one together. :) https://t.co/Q49f1e3eEc
— Stephen Augustus (@stephenaugustus) December 10, 2020
The Technical
Tutorials, tools, and more that take you on a deep dive into the code.
Using Snyk and Podman to scan container images from development to deployment
Matt Jarvis, Red Hat
- Snyk CLIを介して利用できるコンテナスキャン機能と、それをPodmanおよびPodman2.xに搭載されRedHat Enterprise Linux8.3で利用できる新しいPodmanAPIと統合する方法に焦点を当てている。
- SnykとPodmanAPIを使用すると、ローカルコマンドラインで直接コンテナーイメージスキャンが提供され、開発者と管理者がイメージ開発プロセスの最初からイメージをスキャンして脆弱性をチェックするのに役立つ。
Kubernetes: Efficient multi-zone networking with topology aware routing
Bob Killen, Google Cloud
- 先週もこのコーナーで取り上げているため、割愛。
OpenShift/Kubernetes failure stories at scale - Lessons learned from large and dense deployments
Naga Ravi Chaitanya Elluri, Red Hat
- Red Hat社のPerformance and Scalability teamのメンバーとしてツール、ワークロード、および自動化を構築して、実際の本番環境をシミュレートし、クラスターの状態を監視していく中で、何が起こったのか、どのようにデバッグしたのか、そのような状況にならないようにする方法など、以下3つのシナリオについて説明している。
- Scenario 1: Rogue DaemonSet Took Down the 2000 Node Cluster
- Scenario 2: Too Many Objects in Etcd Lead to Writes Being Blocked
- Scenario 3: Hosting Etcd on Slower Disks Created Havoc on the Cluster
Automating volume expansion management - an operator-based approach
Raffaele Spazzoli, Red Hat
- Red Hat社の「Storage, How-tos, Operators, Prometheus, automation」カテゴリーのブログ記事。以前のブログ投稿では、アプリケーションを監視するときに使用するメトリックに関するいくつかのベストプラクティスを解説している。
- 今回は同じメトリックを使用してダッシュボードを作成し、監視対象のいずれかがいつ壊れるかを予測し、場合によっては、先回りして手を打つことにより障害の発生を防ぐことができる方法(予防保全)に解説している。
OPA the easy way feat. Styra DAS!
Amey Deshmukh, InfraCloud Technologies
- StyraDASを使用して、OPAをKubernetesクラスターのアドミッションコントローラーとして構成することに焦点を当てたハンズオンを解説している。
How to use a policy engine to improve your security posture
Nirmata
- 最近のセキュリティー違反が「構成ミス」によるものが大部分を占めていることに触れ、ポリシーエンジンの必要性、役割などを解説している。
Service discovery in Kubernetes - combining the best of two worlds
Ivan Velichko, Booking.com
- タイトル通り、Kubernetesのサービスディスカバリーについて解説している。
- 以下Disclaimerにて、今回の記事で触れていない項目と、理由について記載している。
- Disclaimer: This article intentionally omits the questions of external service (Service type ExternalName) discovering and discovering of the Kubernetes services from the outside world (Ingress Controller). These two deserve a dedicated article each.
Kernel privilege escalation: how Kubernetes container isolation impacts privilege escalation attacks
Kamil Potrec, Snyk
- Kubernetesコンテナの分離が特権昇格攻撃にどのように影響するかを解説している。
GSoD 2020: Improving the API reference experience
Philippe Martin
- GSoD(Google Season of Docs)2020」プロジェクトの一環として、KubernetesのAPI Referenceのドキュメント改善を実施した成果発表。
The Editorial
Articles, announcements, and morethatgive you a high-level overview of challenges and features.
Why Linkerd doesn't use Envoy
William Morgan, Linkerd
- Envoyに敬意を払いつつ、タイトルの「Why Linkerd doesn't use Envoy」を下記の様に触れ解説している。
- Let me also state upfront that this is not an “Envoy sucks” blog post. Envoy is a great project, is clearly a popular choice for many, and we have nothing but respect for the fine folks who work on it. We recommend Envoy to Linkerd users every day in the form of ingress controllers like Ambassador, and there are production systems around the world today where you can find Envoy and Linkerd working side by side.
- So in this article I'm going to do my best to lay out the reasons why in a frank and engineering-focused way. After all, Linkerd is built by engineers and for engineers, and if there's one thing I'm proud of, it's that we've made decisions on the basis of engineering tradeoffs rather than marketing pressure.
- In short: Linkerd doesn't use Envoy because using Envoy wouldn't allow us to build the lightest, simplest, and most secure Kubernetes service mesh in the world.
- FAQも丁寧に書かれていて、とても良心的な記事だと思う。
2021 Predictions: The year that cloud native transforms the IT core
Bill Mann, Styra
- こういったタイトル、中身の記事を見ると年末年始を感じますね。Styra社の2021年の予測Top5は以下の様です。諸々のデータの数字が気になってしょうがない。
- Kubernetes in production will continue to skyrocket, creating new challenges for security and compliance
- We will see significant open source consolidation
- Service mesh will become critical as enterprises scale microservices
- Security and DevSecOps will see expanded responsibilities as new attack
- There will be a complete transformation of the IT core
kubernetes.us10.list-manage.comThe Kubernetes Contributor Celebration starts in about 80 minutes, feel free to join us, and if you're a contributor in OSS in general, we would love to have you stop by! https://t.co/yYHHTGvLLS
— Jorge Castro (@castrojo) December 11, 2020
Upcoming CNCF webinars
気になるWebinarがあれば登録してチェックを。以下は直近のものとしてリストされていたものです。
Member Webinar: Power to the people – making root/Docker a reality inside a Gitpod Container
Christian Weichel, Chief Architect @Gitpod
Alban Crequy, Director of Kinvolk Labs @Kinvolk
Dec 11, 2020 10:00 AM Pacific Time
REGISTER NOW »
Member Webinar: Implementing automated managed k8s service
Mason Choi, Senior Engineer @Samsung SDS
Kangsub Song, Senior Engineer @Samsung SDS
Dec 15, 2020 10:00 AM Korea Time
REGISTER NOW »
Member Webinar: Reducing your Kubernetes cloud spend
Webb Brown, CEO @Kubecost
Dec 15, 2020 10:00 AM Pacific Time
REGISTER NOW »
Member Webinar: Argo: Real Enterprise-scale with K8s
Al Kemner, Principal Software Engineer and Architect @New Relic
Daniel Jimbel, Staff Engineer @New Relic
Caleb Troughton, Product Manager, Telemetry Data Platform @NewRelic
Dec 16, 2020 7:00 AM Pacific Time
REGISTER NOW »
Member Webinar: Machine learning for K8s logs and metrics
Larry Lancaster, Founder and CTO @Zebrium
Dec 16, 2020 1:00 PM Pacific Time
REGISTER NOW »
Member Webinar: Kubernetes configuration – Auditing for enterprise best practices through open source tooling
Kendall Miller, President @Fairwinds
John Wynkoop, Cloud CTO @IGNW
Dec 18, 2020 10:00 AM Pacific Time
REGISTER NOW »
いかがでしたか?気になる記事や情報はありましたか?
私もまだ内容を咀嚼出来ていないものが多々ありますので、この備忘録兼リンク集を活用しながら理解を深めていきたいと思います。
では、また。
Bye now!!