- はじめに
- なぜ Mackerel、なぜ今なのか
- Mackerel のβ版が実際にサポートしているもの
- アーキテクチャの選択: Collector 経由か直接送信か
- ギャップ: 直接送信経路が送れなかった Mackerel 必須のヘッダー
- 2つ目のギャップ: 認証は直ったが、ペイロード形式は直っていなかった
- それでも「9ベンダー全E2E検証済み」の一覧に含めていない理由
- セキュリティ上の注意
- トラブルシューティングの切り分け
- 段階的な導入ステップ
- 今すぐ試せること
- まとめと次のステップ
- リソース
はじめに
Mackerel は2026年7月16日、OpenTelemetry を基盤とするログ機能をオープンβとして公開しました。
これを受けて、Amazon FSx for NetApp ONTAP のファイルアクセス監査ログ、EMSイベント、FPolicyイベントを複数の Observability バックエンドへ配信するOSSリポジトリに、Mackerel 向けの統合を追加しました。
OTel Collector 経由では、Mackerel 向け exporter を追加するだけで送信できました。一方、Lambda から Mackerel へ直接送信する経路では、次の2つの互換性ギャップが見つかりました。
Bearer/Basicではなく、Mackerel-Api-Keyという独自ヘッダーが必要- OTLP/JSON ではなく、OTLP/Protobuf で送信する必要がある
本記事では、この2つの問題に対して追加した汎用認証ヘッダー機能と、限定的な軽量 Protobuf エンコーダーについて説明します。Collector 経由と直接送信の両方で実アカウントへの E2E 送信を確認していますが、Mackerel ログ機能自体はまだβ版です。そのため、本番では Collector 経由を基本とし、監査ログの唯一の保管先としては扱わない前提で評価します。
対象スコープ: 本記事の対象は、FSx for ONTAP から取得したファイルアクセス監査ログ、EMS イベント、FPolicy イベントを、既存の Lambda/OTel Collector 統合から Mackerel へ送信する経路です。
本記事で扱わない範囲: Collector 自体の高可用化、Lambda の再試行・DLQ 設計、外向き通信経路(NAT Gateway を利用する構成を含む)、ログ欠損時の再処理については、ベース記事(第3回)とリポジトリの運用設計ドキュメントを参照してください。
FSx for ONTAP
├─ File access audit (EVTX/XML)
├─ EMS events
└─ FPolicy events
│
▼
Lambda: OTLP Logs Data Model を生成
│
├──▶ OTel Collector ──▶ Mackerel 〔推奨〕
│
└──▶ Mackerel へ直接送信 〔検証経路〕
- Mackerel-Api-Key ヘッダー
- Accept: */*
- OTLP/Protobuf 必須
GitHub: Yoshiki0705/fsxn-observability-integrations 新規ファイル:
integrations/mackerel/、integrations/otel-collector/otel-collector-config-mackerel.yaml変更ファイル:integrations/otel-collector/lambda/{handler,ems_handler,fpolicy_handler}.py
本記事は「FSx for ONTAP サーバーレス Observability」シリーズの単発記事です — インシデント対応の記事(第6回)の続きではなく、その記事を読んでいることを前提にしません。ベースにしているのは 第3回(ベンダー中立な OTel Collector パターン)です。新しいバックエンドが接続される仕組みそのものだからです。
なぜ Mackerel、なぜ今なのか
このシリーズでは、これまで Datadog、Splunk、Grafana Cloud、Honeycomb など9つの Observability プラットフォームへ、FSx for ONTAP の監査ログを配信し、実際のアカウントで届くところまで確認してきました。日本のユーザーの方から「Mackerel は対応しないのか?」というお声を何度かいただいていて、正直なところずっと気になっていました。
結論からお伝えすると、これまで対応してこなかった理由は単純です。本リポジトリ側の都合ではなく、Mackerel 自身にログを送る機能そのものがまだ存在しなかったからです。Mackerel は以前から OpenTelemetry ベースのトレーシング(APM)機能を提供していましたが、ログはずっと同社の製品側のギャップでした。
この記事にはもう一つ、直接のきっかけがあります。SRE NEXT 2026 に参加した際、Mackerel を開発されている旧知の方々と、Amazon FSx for NetApp ONTAP の Observability について立ち話程度に相談させてもらう機会がありました。その場のやりとり自体がすぐに何かへ直結したわけではありませんが、カンファレンス全体を通じてインフラ領域の開発に対するヒントとモチベーションを得られたことが、今回の統合に取り組む後押しになっています。
その状況が変わったのが 2026年7月16日。Mackerel がログ機能をオープンβとして公開しました。「待っていた機能がついに来た」というのが正直な感想で、この記事を書きたくなった直接のきっかけです。
ただし、公開されたばかりのβ版という点は無視できません。機能そのものが新しく、明示的に正式版ではないという状況は、すでに成熟した8番目・9番目のベンダーを何も気にせず追加するのとは、正直だいぶ話が違います。この記事では、実際に手を動かして分かったつまずきポイントと、それでもなお「対応ベンダー一覧」に静かに混ぜ込むのではなく別枠で扱うことにした理由をお伝えします。
ベンダー中立に関する補足: 本記事は、Mackerel の OTLP ログ取り込みを技術的な観点のみで評価しています。これは本リポジトリの vendor-comparison.md が Datadog、Grafana、Splunk、その他9ベンダーを扱う姿勢と同じです。この比較においてどのプラットフォームも他より優れているという枠組みでは扱っていません。それぞれが異なる文脈に適しており、ここでの目的は「実際に何が対応しているか」を記録することであり、「どちらが優れているか」を順位付けすることではありません。
この統合が適する環境
- 既に Mackerel を監視/APM に利用している
- FSx for ONTAP のイベントを既存の障害調査フローに統合したい
- OTel Collector を共通のテレメトリールーターとして利用している
- β機能を非本番または補助的な経路として評価できる
現時点では別の選択肢を検討する環境
- 法令・監査要件上、データ保持の保証が必要
- セキュリティログの唯一の保存先として利用する
- ログ欠損が許容されず、正式なサポート条件が必要
- データレジデンシーや契約経路に厳格な条件がある
Mackerel 公式は、一部のパートナープログラム経由の契約では利用できない場合がある旨を明記しています。導入前に契約形態を確認してください。
Mackerel のβ版が実際にサポートしているもの
統合コードを書く前に最初に行ったのは、ログがトレースと同じように動くと決めつけず、Mackerel 自身のドキュメントを確認することでした。2026年7月時点で、Mackerel 公式ドキュメントが案内するログ送信方式は OpenTelemetry 経由です。本記事でも OTLP/HTTP を使用します。共通する部分とそうでない部分が判明しました。
 Mackerel のログ機能トップ画面。β版であることの注意事項(データ保持の非保証、臨時メンテナンスの可能性)が明示されている
Mackerel のログ機能トップ画面。β版であることの注意事項(データ保持の非保証、臨時メンテナンスの可能性)が明示されている
| Mackerel トレーシング(APM) | Mackerel ログ(β版、2026-07-16) | |
|---|---|---|
| プロトコル | OTLP/HTTP | OTLP/HTTP(同一) |
| エンドポイント | https://otlp-vaxila.mackerelio.com |
同一エンドポイント |
| 認証 | Mackerel-Api-Key ヘッダー(Write 権限) |
同一ヘッダー、同一権限 |
| 必須の追加ヘッダー | Accept: */*(Mackerel の公式ドキュメントで必須と明記されているが、その理由自体は公開されていない) |
同じ要件 |
| グルーピングキー | — | service.namespace + service.name の resource attribute |
| 保存期間 | (APM 独自の条件) | 正式版で30日間を予定。β版も同条件だが保証なし |
| Collector 送信バッチ設定 | — | 約3.5MB(sending_queue.batch.max_size: 3500000 バイト)。Mackerel 公式設定例に合わせた Collector 側の値であり、API の絶対的な最大リクエストサイズを意味するものではない |
実務上の結論としては、既に OTel Collector でトレースを Mackerel に送信している場合、ログの追加は新しい統合パターンではなく、2つ目の exporter パイプライン設定にすぎません。
アーキテクチャの選択: Collector 経由か直接送信か
通常は Collector 経由を推奨します。 直接送信は、Collector を運用しない小規模構成や、プロトコル互換性を検証する場合の選択肢です。Mackerel 公式もコレクターを間に置く構成を推奨しています(公式ヘルプ: Mackerel にログを送信する)。
| 判断基準 | 推奨経路 |
|---|---|
| 本番運用、マスキング、複数送信先、再送制御が必要 | Collector 経由 |
| コンポーネント数を最小化したい小規模環境 | 直接送信 |
| Mackerel 統合をまず試したい | ローカル Collector テスト |
| セキュリティ監査ログを扱う | 原則 Collector 経由(機微情報をフィルタ/除外) |
本リポジトリの OTel Collector 統合は既に、単一の Lambda コードベースから FSx for ONTAP の監査ログ/EMS/FPolicy ログを Datadog、Grafana Cloud、Honeycomb へ同時配信しています — Lambda がバックエンド中立の OTLP ペイロードを構築し、Collector の exporters 設定が配信先を決めます。このパターンに Mackerel を4番目のバックエンドとして追加するのに、Lambda 側の変更は一切不要でした:
# otel-collector-config-mackerel.yaml # NOTE: 本リポジトリで検証した Collector バージョン (0.152.0) では otlp_http を使用しています。 # 古いバージョンでは otlphttp(アンダースコアなし)が必要な場合があります。 # 利用バージョンのドキュメントを確認してください。 exporters: otlp_http/mackerel: endpoint: https://otlp-vaxila.mackerelio.com headers: Accept: "*/*" Mackerel-Api-Key: ${env:MACKEREL_APIKEY} sending_queue: batch: max_size: 3500000 sizer: bytes service: pipelines: logs: receivers: [otlp] exporters: [otlp_http/mackerel]
Collector 経由の統合としては、これで完結します。しかし本リポジトリには、Collector を完全にスキップして Lambda がベンダーの OTLP エンドポイントへ直接送信する直接送信経路もあります(Grafana Cloud 向けに AUTH_MODE=basic で既に使われています)。この経路も Mackerel で動くかを確認したところ、より興味深い展開になりました。
ギャップ: 直接送信経路が送れなかった Mackerel 必須のヘッダー
「exporter を追加すれば終わり」は、すべての経路には当てはまりませんでした。実際の Lambda コード(handler.py、ems_handler.py、fpolicy_handler.py)を確認すると、直接送信の認証ロジックは2つのモードしか対応していないことが分かりました。
if AUTH_MODE == "basic": encoded = base64.b64encode(token.encode("utf-8")).decode("utf-8") auth_headers = {"Authorization": f"Basic {encoded}"} else: auth_headers = {"Authorization": f"Bearer {token}"}
Mackerel の認証はどちらでもありません。Bearer/Basic のラップなしの、単純な独自ヘッダー Mackerel-Api-Key: <トークン> です。この時点では、Collector を経由しない Mackerel への直接送信は不可能でした。
対応内容は Mackerel 専用の分岐ではなく、汎用のプリミティブです。
AUTH_MODE = os.environ.get("AUTH_MODE", "bearer") # "bearer"、"basic"、または "header" AUTH_HEADER_NAME = os.environ.get("AUTH_HEADER_NAME", "Authorization") EXTRA_HEADERS_JSON = os.environ.get("EXTRA_HEADERS_JSON", "") # ... elif AUTH_MODE == "header": auth_headers = {AUTH_HEADER_NAME: token} # ... if EXTRA_HEADERS_JSON: extra_headers = json.loads(EXTRA_HEADERS_JSON) auth_headers = {**(auth_headers or {}), **extra_headers}
AUTH_MODE=header は、指定した任意のヘッダー名でシークレットをそのまま送信します。Mackerel が最初の利用者になりましたが、このオプション自体に Mackerel への言及は一切ありません。EXTRA_HEADERS_JSON は Mackerel が必須とする Accept: */* に対応します。これは認証ではなく、Mackerel のバックエンドが依存している単なる静的ヘッダーです。
EXTRA_HEADERS_JSONの制約:Acceptなどの静的な非シークレットヘッダー専用です。認証ヘッダー(Authorization、Mackerel-Api-Keyなど)、Content-Type、Content-Length、Hostを指定しないでください。これらはAUTH_MODE/OTLP_CONTENT_TYPEの設定や HTTP ライブラリによって自動的に設定されます。
同じ修正を ems_handler.py と fpolicy_handler.py にも適用しました。CloudFormation テンプレートはこれらの環境変数を3つの Lambda 関数全てに渡しているため、1つだけにパッチを当てると、残り2つが AUTH_MODE=header を黙って無視してしまいます。
3つのハンドラーに合計12件の単体テストを追加してこれを検証しています(handler.py・ems_handler.py・fpolicy_handler.py に4件ずつ)。カスタムヘッダー認証、EXTRA_HEADERS_JSON のマージ、API キーシークレットが設定されていない場合でも追加ヘッダーが適用されるケース、不正な EXTRA_HEADERS_JSON を設定した場合に起動時に警告を出力し追加ヘッダーなしで継続するケースを確認するテストです。変更したテンプレートと新規ファイルに対する cfn-lint と gitleaks もクリーンです。
2つ目のギャップ: 認証は直ったが、ペイロード形式は直っていなかった
認証の修正は終わりではありませんでした。単体テストは HTTP 層を完全にモックしているため通過していましたが、実際の API キーで呼び出すと2つ目の問題が見つかりました。
OTLP endpoint error 400: {"code":400,"message":"json is not supported yet"}
_send_otlp_payload は常に Content-Type: application/json で OTLP/JSON を送信していましたが、Mackerel の OTLP エンドポイントは Protobuf のみを受理し、JSON を明示的に拒否します。Collector 経由の経路ではこの問題が一度も表面化しませんでした。Collector は受信した OTLP データを内部データモデルへデコードし、Mackerel 向けの otlphttp exporter で再シリアライズします。otlphttp exporter のデフォルトエンコーディングが Protobuf(proto)であるため、Lambda から Collector までの入力形式が OTLP/JSON であっても、Collector から Mackerel へは OTLP/Protobuf で送信されます。直接送信の Lambda コード自体には Protobuf エンコーダーが元々存在しなかったのです。
本プロジェクトは、Lambda のデプロイパッケージに追加の Python 依存パッケージを含めない方針です。Lambda ランタイム環境で利用可能な boto3/urllib3 のみを使用しており、protobuf/opentelemetry-proto は同梱していません。このベンダー1社のためだけにパッケージを追加するのは不釣り合いなため、対応は小規模な自作エンコーダー(otlp_protobuf.py)にしました。このエンコーダーは汎用的な OTLP 実装ではありません。本リポジトリが生成する FSx for ONTAP ログの限定されたデータ構造(timeUnixNano、severityNumber、severityText、body.stringValue、attributes(stringValue のみ)、resource attributes(stringValue のみ)、InstrumentationScope)だけを対象としています。OTLP Logs の全フィールド・全型をサポートするものではなく、他用途への転用は想定していません。フィールド番号は OTLP公式 proto定義(Apache License 2.0)からそのまま取得し、公式の opentelemetry-proto 生成 Python クラスを使った一時的な virtualenv でバイト単位の一致を確認済みです。公式 proto 定義の更新を監視し、互換性テストを継続します。
OTLP_CONTENT_TYPE = os.environ.get("OTLP_CONTENT_TYPE", "json") # "json" または "protobuf" if content_type == "protobuf": headers = {"Content-Type": "application/x-protobuf"} body = encode_logs_data(payload) else: headers = {"Content-Type": "application/json"} body = json.dumps(payload).encode("utf-8")
OTLP_CONTENT_TYPE=protobuf を追加した後、handler.py の実際の build_otlp_payload・_send_otlp_payload 関数(再実装ではなく、Lambda が実際に実行する同じコード)を、実際の Mackerel API キーに対して直接呼び出したところ成功しました。検証では、今回送信した2件のサンプルレコードについて、操作種別(ReadData/Delete)、結果(Success/Access Denied)、ファイルパス、SVM名、ユーザー情報、イベント時刻など、本リポジトリが生成するサンプル属性が Mackerel 上で検索可能な状態で保持されることを確認しました。
単体テストは認証ヘッダー、Content-Type 分岐、エンコード結果を検証します。一方、ベンダー側の受付仕様、レート制限、ネットワーク経路、検索反映までの遅延は検出できないため、実エンドポイントを使った E2E テストを別に実施しています。3つのハンドラーに3件ずつ(新しい content-type 分岐のテスト)と専用の test_otlp_protobuf.py に11件、合計20件の単体テストを追加し、OTel Collector 統合のテストスイートは110件パスになりました。
あるベンダーの1つの配信経路を検証したことは、別の経路の検証にはなりません。認証ヘッダー、ペイロードの伝送形式、ネットワークの到達性は、それぞれ独立して失敗しうる別の要素です。HTTP 層をモックした単体テストスイートは、実際のベンダーエンドポイントだけが強制するペイロード形式の不一致を検出できません。
それでも「9ベンダー全E2E検証済み」の一覧に含めていない理由
本リポジトリの他の全ベンダーには、それぞれ理由のあるチェックマークが付いています。実際のペイロードを実在のアカウントに送信し、到着を確認済みだということです。Mackerel も今回そのチェックマークを獲得しました。Collector 経由の経路、OTLP_CONTENT_TYPE=protobuf を追加した後の直接送信経路、両方で送信したサンプル FSx 監査ログペイロードが、Mackerel のログ検索 UI 上で本リポジトリが生成した監査属性の検索・確認ができています。
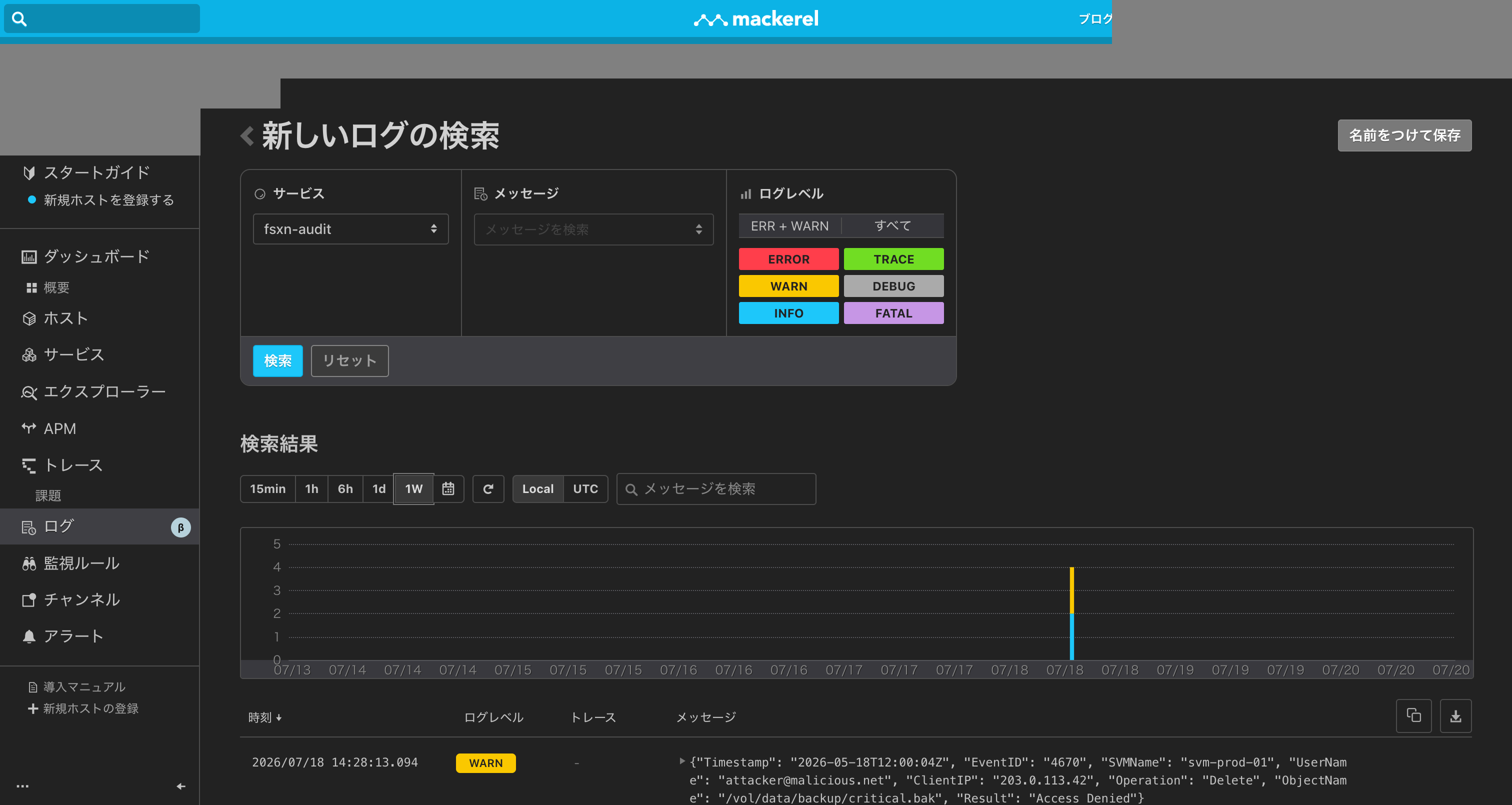 E2E検証の証跡: fsxn-audit サービスで検索した結果。ReadData/Success、WriteData/Success、Open/Failure、Delete/Access Denied の4件が WARN/INFO レベルで表示されている(スクリーンショット中の IP アドレス 203.0.113.x は RFC 5737 で定義されたドキュメント用アドレスブロック TEST-NET-3 であり、実在する環境のアドレスではない)
E2E検証の証跡: fsxn-audit サービスで検索した結果。ReadData/Success、WriteData/Success、Open/Failure、Delete/Access Denied の4件が WARN/INFO レベルで表示されている(スクリーンショット中の IP アドレス 203.0.113.x は RFC 5737 で定義されたドキュメント用アドレスブロック TEST-NET-3 であり、実在する環境のアドレスではない)
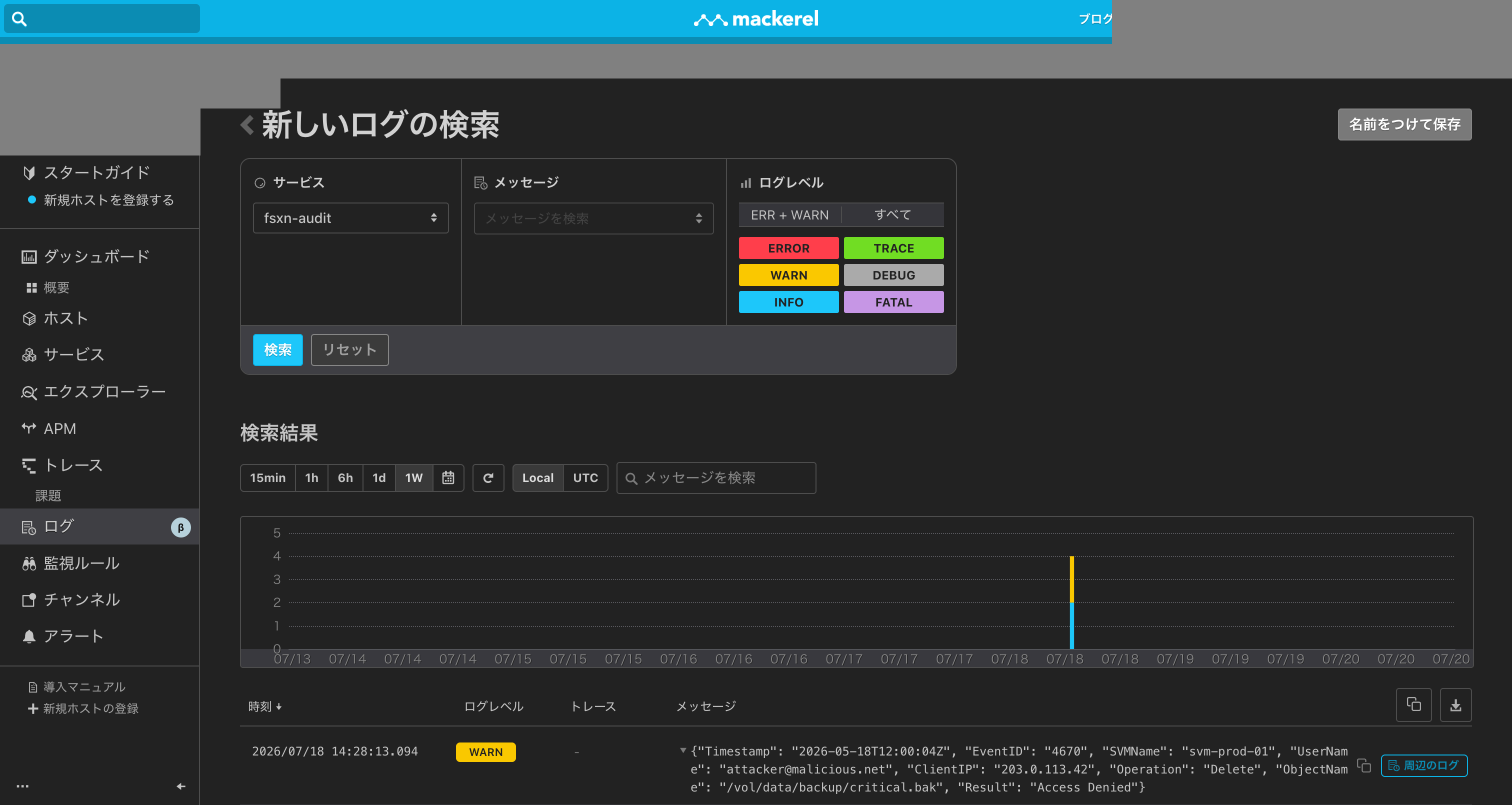 ログ詳細: 操作種別、結果、SVM名、ファイルパス、ユーザー情報、クライアントIP、タイムスタンプなどの属性が検索可能な状態で保持されている(IP アドレスおよびメールアドレスはサンプルデータであり、RFC 5737 TEST-NET-3 および架空ドメインを使用)
ログ詳細: 操作種別、結果、SVM名、ファイルパス、ユーザー情報、クライアントIP、タイムスタンプなどの属性が検索可能な状態で保持されている(IP アドレスおよびメールアドレスはサンプルデータであり、RFC 5737 TEST-NET-3 および架空ドメインを使用)
本リポジトリの README.md もこれを反映しています:
✅ E2E 検証済み(オープンβ) — 実際のアカウントへの E2E 送信は確認済みだが、送信先プラットフォームの機能自体がオープンβ版(データ保持の保証なし、予告なしのメンテナンスの可能性あり)。
| 検証条件 | 値 |
|---|---|
| E2E 検証日 | 2026-07-18 |
| Collector バージョン | 0.152.0(OpenTelemetry Collector Contrib) |
| リージョン | ap-northeast-1 |
| リポジトリコミット | 記事公開時点の main ブランチ HEAD |
コード側の条件はこれで満たされました。それでも主要な一覧に含めていない理由がもう一つあり、これは本リポジトリのコードとは無関係です。Mackerel 自身が公開している以下の内容についてのものです。
- β期間中のデータ保持は保証されない
- 予告なしのメンテナンスが発生する可能性がある
- 正式リリースは2026年秋頃を予定。正確なGA日付自体は未確定
費用に関する補足: 2026年7月時点で、β期間中は無料です。正式版ではログのインジェスト量に応じた課金が予定されています。記事公開後に料金・計測単位・無料枠が変更される可能性があるため、最新条件はMackerel 公式の料金情報を確認してください。
この統合を「対応ベンダー一覧」に、他の9ベンダーと同じチェックマークで静かに組み込んでしまうと、セキュリティアラート用途(本リポジトリの自動インシデント対応モジュールなど)でこれをデプロイする人は、Datadog や Splunk と同程度の信頼性を当然のように想定してしまいます。その想定は、本リポジトリのコードの不備ではなく、その下にあるプラットフォーム自体が明示的に正式版前であることによって誤りとなります。そのため、この統合は Mackerel 自身が正式リリースに到達するまで、vendor-comparison.md の別枠「検証中・β版ベンダー」セクションに、E2E検証済み・β版であることを明記した状態で置いています。
今回の検証を再現する人向けに一点だけ補足します。調査中はブラウザ内部で利用される GraphQL リクエストも参照しましたが、これは公開・安定 API として提供されていることを確認したものではありません。そのため、本リポジトリの恒久的な E2E インターフェースとしては依存せず、最終確認は公式 UI の検索画面と Collector の送信メトリクス(otelcol_exporter_sent_log_records)を組み合わせて実施しています。Mackerel 側の内部実装が変更されれば、同名のクエリが動作しなくなる可能性があります。
セキュリティ上の注意
FSx for ONTAP の監査ログには、ユーザー名、ファイルパス、共有名、クライアント IP アドレスなどが含まれる場合があります。組織によっては機微情報や個人関連情報に該当し得る内容です。本番データを外部 Observability サービスへ送信する前に、以下を確認してください。
- 組織のデータ分類、保存場所、アクセス制御、保持期間の要件
- 必要に応じて、OTel Collector の
filter/transformプロセッサーで機微な属性を削除またはマスキング(本リポジトリの PII redaction cookbook も参照) - β期間中の Mackerel を、監査証跡の唯一の保存先として使用しないこと
EXTRA_HEADERS_JSON に関する注意:
- シークレット値を入れない(API キーは Secrets Manager に保持する)
- CloudFormation パラメータや Lambda 環境変数へ直接 API キーを入れない
- ログ出力時にヘッダー全体を出力しない
トラブルシューティングの切り分け
問題が発生した場合、以下の4層で切り分けてください。
| 層 | 確認対象 | 主な確認内容 |
|---|---|---|
| 1. 生成 | Lambda | OTLP レコード数、必須属性、時刻、severity、resource attributes。デバッグログを有効にする場合も、ファイルパスやユーザー名などの機微情報を出力しないこと |
| 2. 送信 | Lambda/Collector exporter | HTTP 応答コード、タイムアウト、再試行結果(400・401・403・429・5xx) |
| 3. 受理 | Collector メトリクス/OTLP 応答 | sent/failed log records、partial success、ドロップ有無 |
| 4. 利用 | Mackerel UI | service 属性の一致、検索時間範囲、フィルター条件、反映遅延 |
Collector/HTTP 送信側の失敗(層2〜3)と、Mackerel に受理された後の検索・表示上の問題(層4)を混同しないことが重要です。Mackerel が HTTP 400 で拒否した場合は層2〜3の問題であり、層4ではありません。詳細は integrations/mackerel/docs/ のトラブルシューティング表を参照してください。
段階的な導入ステップ
β版の統合を評価する場合、以下の段階を推奨します。
- サンプルログでローカル Collector の E2E 検証(
test-local-mackerel.sh) - 非本番の FSx for ONTAP 監査ログを限定送信
- 送信量、欠損、検索性、機微情報を評価
- 本番では既存ログ基盤(CloudWatch Logs、S3、既存ベンダー)への二重送信を実施
- β期間中は Mackerel を唯一の監査証跡保存先にしない
- 正式版でデータ保持条件、サポート条件、料金体系が確定した段階で主系化を判断
今すぐ試せること
以下の両経路とも、E2E で動作確認済みです:
# Collector 経由(推奨、Lambda 側の変更不要) cp integrations/otel-collector/.env.mackerel.example .env.mackerel # .env.mackerel を Write 権限のある Mackerel API キーで編集 bash integrations/otel-collector/scripts/test-local-mackerel.sh
# 直接送信(Collector を経由しない。AUTH_MODE=header と OtlpContentType=protobuf の両方が必要)
aws cloudformation deploy \
--template-file integrations/otel-collector/template.yaml \
--stack-name fsxn-otel-integration \
--parameter-overrides \
OtlpEndpoint=https://otlp-vaxila.mackerelio.com \
AuthMode=header \
AuthHeaderName=Mackerel-Api-Key \
ExtraHeadersJson='{"Accept":"*/*"}' \
OtlpContentType=protobuf \
ApiKeySecretArn=<secret-arn> \
... \
--capabilities CAPABILITY_NAMED_IAM
OtlpContentType=protobuf は Mackerel では省略できません — 指定しないと、認証が正しくても上記の JSON 拒否エラーで送信が失敗します。
完全なセットアップガイド(日英バイリンガル)は integrations/mackerel/docs/ にあります。トラブルシューティング表には、間違った層をデバッグする前に Collector 側の失敗と Mackerel 側の拒否を切り分けるよう明示的に記載しています。
まとめと次のステップ
Mackerel のログ機能β版への OTLP 配信対応、いかがでしたでしょうか。実際に手を動かしてみると、Collector 経由だけを検証していると表面化しにくい2つの互換性ギャップがあり、どちらも実際の API キーで直接送信を試すまでは見えてきませんでした。
今回追加した AUTH_MODE=header、EXTRA_HEADERS_JSON、OTLP_CONTENT_TYPE=protobuf は、Mackerel 専用のコードではなく、今後 OTLP/HTTP エンドポイントに独自認証ヘッダーや Protobuf 必須要件を持つ他のバックエンドが追加される場合にも、そのまま再利用できる汎用プリミティブです。
次にやることは、以下の3つだと考えています。
- Mackerel のログ機能の正式リリース告知(データ保持条件、料金体系)を待つこと。発表があれば、本記事とリンク先のドキュメントも古い情報のまま放置せず更新します。
- 正式版でデータ保持条件、サポート条件、料金体系が確定した段階で、Mackerel を「検証中・β版ベンダー」から主要な「対応ベンダー一覧」比較表へ移行すること。
- すでに Mackerel を運用されている方は、セットアップガイドのサンプル OTLP ペイロードを使って、自分のオーガニゼーションでも独立して動作確認してみてください。
Mackerel のログ機能は、正式リリースに向けてこれからさらに育っていく機能だと思います。日本発の Observability プラットフォームとして、これからの進化も楽しみにしています。
このブログが、どなたかの参考になれば幸いです。
では、また。