- The English Version of this blog is here.
- この記事は2021/5/30~2021/6/4発行の下記3つのWeekly Reportを読み、備忘録兼リンク集として残しているものです。
- なるべく情報を早く届けたい/共有したいので、ブログのリンクを確認次第、先行公開しています。自身のコメントは随時追加しています。
- DEVOPS WEEKLY ISSUE #544 May 30th, 2021
- News
- The DORA/Google State of Devops survey is open, focusing this year on metrics, how SRE fits with Devops, security and compliance, distributed teams and more.
- A post on providing on-demand test environments for growing development teams, supported by a developer portal.
- OpenSLO is a service level objective (SLO) language that declaratively defines reliability and performance targets using a simple YAML specification. Store your SLOs in Git, with tooling to help validation in your CI pipeline.
- A post on the reality of cloud costs as organisations grow. Lots of useful insights into public data, mainly pointing out it’s more nuanced at scale for certain types of workloads.
- A reminder that system complexity can easily reduce uptime of the whole. The examples are simplistic, ignoring partial failures, but still a useful example to bear in mind.
- A post on profiling production services using Prometheus and Jaeger.
- An in-depth look at autoscaling in Kubernetes. What problems does it solve, how is it implemented and how it works under-the-hood.
- Delta sharing is an open protocol for secure real-time exchange of large datasets, aiming to enable secure data sharing across products.
- Tools
- News
- SRE Weekly Issue #272 May 30th, 2021
- Articles
- [Salesforce] Multi-Instance Service Disruption on May 11-12, 2021
- That Salesforce outage: Global DNS downfall started by one engineer trying a quick fix
- @ReinH on Twitter Re: Salesforce Outage
- Subverting the process
- Building an SRE Team? How to Hire, Assess, & Manage SREs
- The Advanced Principles of Chaos Engineering
- Why do config changes keep coming up in major incidents?
- Outages
- Articles
- KubeWeekly #264 June 4th, 2021←メルマガを受領。(2021/06/06 04:20JST)
The English Version of this blog is here.
この記事は2021/5/30~2021/6/4発行の下記3つのWeekly Reportを読み、備忘録兼リンク集として残しているものです。
なるべく情報を早く届けたい/共有したいので、ブログのリンクを確認次第、先行公開しています。自身のコメントは随時追加しています。
- 誰かの情報源や検索工数削減などになれば幸いです。
DEVOPS WEEKLY ISSUE #544 May 30th, 2021
SRE Weekly Issue #272 May 30th, 2021
KubeWeekly #264 June 4th, 2021←メルマガを受領。(2021/06/06 04:20JST)
- この記事を読んで疑問点や不明点があれば、URLから本文をご確認の上、ご指摘頂ければ幸いです。
- 理解が浅いジャンルも、とにかくコメントする様にしていますので、私の勘違いや説明不足による誤解も多々あろうかと思います。
- 情報量が多いので文字とリンクだけに絞っております。
- 各レポートで取り上げられている記事には2020年以前のものもあり、必ずしも最新のものという訳ではない様です。
DEVOPS WEEKLY ISSUE #544 May 30th, 2021
News
The DORA/Google State of Devops survey is open, focusing this year on metrics, how SRE fits with Devops, security and compliance, distributed teams and more.
- 上記の通り、「DORA/Google State of Devops survey」がオープンに。
- Surveryはこちらから。
A post on providing on-demand test environments for growing development teams, supported by a developer portal.
- タイトルは「The process: Building on-demand staging environments at Paystack」。
- 上記のEditorコメント通り、開発チームを拡大しつつデプロイ時間を短縮し、開発者の効率を向上させるために、Kubernetes を活用してオンデマンドのテスト環境を提供する方法を共有している。
OpenSLO is a service level objective (SLO) language that declaratively defines reliability and performance targets using a simple YAML specification. Store your SLOs in Git, with tooling to help validation in your CI pipeline.
- 先週のSRE Weekly Issue #271で取り上げた記事「Nobl9 Makes SLO Specification Open Source」で出てきたOpen SLOのWebページ。
A post on the reality of cloud costs as organisations grow. Lots of useful insights into public data, mainly pointing out it’s more nuanced at scale for certain types of workloads.
- タイトルは「The Cost of Cloud, a Trillion Dollar Paradox」。
- 以下のグラフ、total cost of revenue (COR)の観点などを交えて、タイトルの内容を解説している。
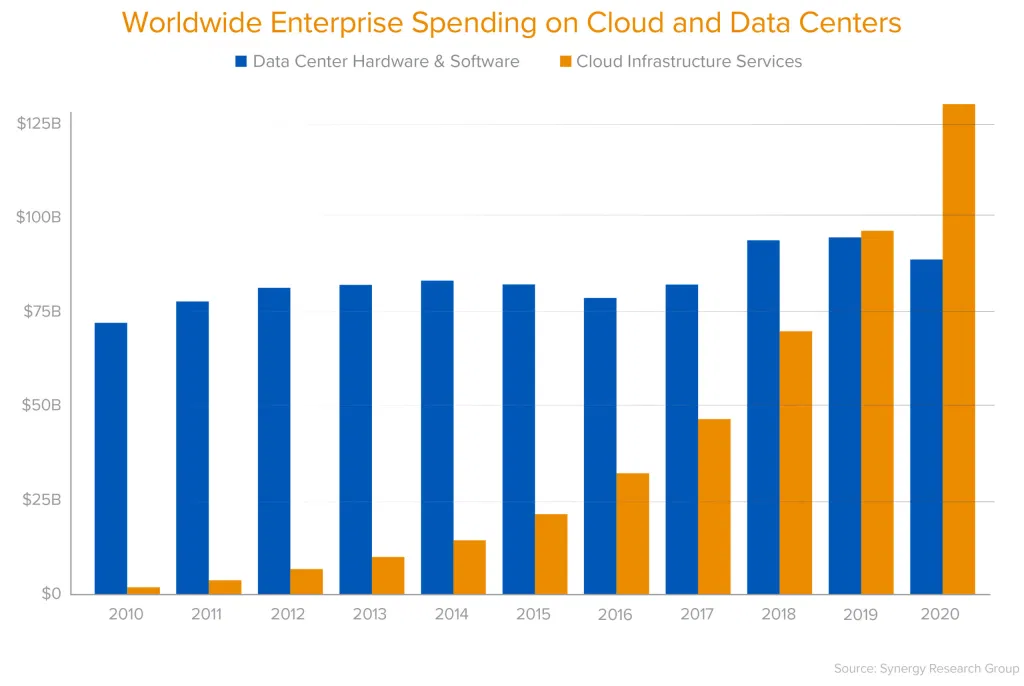
A reminder that system complexity can easily reduce uptime of the whole. The examples are simplistic, ignoring partial failures, but still a useful example to bear in mind.
- タイトルは「How Systems Complexity Reduces Uptime」。
- 先週のSRE Weekly Issue #271で取り上げたため、割愛。
A post on profiling production services using Prometheus and Jaeger.
- タイトルは「Profiling in production to detect server bottlenecks」。
- 上記のタイトルとEditorのコメントの記載の通り、成長を続けるMiro社でサーバーのボトルネックをPrometheusとJaegerを使って特定して対処している話を共有している。
- 凄い成長率。
- From March to November 2020 Miro grew sevenfold, hitting up to 600+ thousand unique users per day.
An in-depth look at autoscaling in Kubernetes. What problems does it solve, how is it implemented and how it works under-the-hood.
- タイトルは「Horizontal Pod Autoscaler in Kubernetes」。
- 以前KubeWeekly #260 April 23rd, 2021で取り上げられた際にコメントしているため、割愛。
Delta sharing is an open protocol for secure real-time exchange of large datasets, aiming to enable secure data sharing across products.
- セキュアなデータ共有のオープンプロトコル「Delta Sharing」のWebページ。
- Delta Sharingの仕組みと、筆者がデータ共有へのオープンなアプローチに非常にエキサイトしている理由について説明している紹介記事はこちら。
Tools
Open Policy Agent, and it’s Rego language, can be applied to lots of different problems. Confectionary provides a set of policies for testing Terraform plans. My hope is we’ll see more of these sorts of pre-packaged policies.
- Conftestツールのルールのライブラリー「Confectionery」のGitHubページ。
SRE Weekly Issue #272 May 30th, 2021
Articles
[Salesforce] Multi-Instance Service Disruption on May 11-12, 2021
Salesforce has posted a ton of information about their major outage two weeks ago. It involved a change to their DNS system that combined with an issue in BIND daemon shutdown that prevented it from starting back up.
The analysis goes into great detail on the fact that an engineer used the Emergency Break-Fix (EBF) process to rush out the DNS configuration change.
In this case, the engineer subverted the known policy and the appropriate disciplinary action has been taken to ensure this does not happen in the future.
Thanks to an anonymous reader for pointing this out to me.
Salesforce
- Salesforce社の障害の報告記事。日本語では「2021 年 5 月 12 日発生のマルチインスタンスサービス中断について」というタイトル。上記のEditorのコメントに含まれる情報などが含まれている。
- 下の記事を読む前に概要を頭に入れておくと理解が進む。
That Salesforce outage: Global DNS downfall started by one engineer trying a quick fix
This article calls out the heavily blame-ridden language in the above incident analysis and the briefing given by Salesforce’s Chief Reliability Officer.
I’m dismayed to see such language from someone who is at the C-level for reliability.
“For whatever reason that we don’t understand, the employee decided to do a global deployment,” Dieken went on.
Richard Speed — The Register
- 上記のEditorのコメントと同様の感想。こういった言葉はそのポジションの方から聞きたくない。自身の役割を果たしていないどころか、貶めている。自身向けであろうと、自社の仲間向けであろうと、何かあった際にこうした言葉が発せられる組織には残りたくないでしょうね。
@ReinH on Twitter Re: Salesforce Outage
…and the Twittersphere agrees with me.
If you want to blame someone, maybe try blaming the “chief availability officer” who oversees a system so fragile that one action by one engineer can cause this much damage. But it’s never that simple, is it.
@ReinH on Twitter
- Salesforce社の上の記事のChief Reliability Officerのコメントに対してい、Editorと同じ意見を述べているツイートの抜粋。
Subverting the process
Another really great take on the Salesforce outage followup.
Lorin Hochstein
- 引き続き、Salesforce社の障害に関する記事。以下の点に同意。ユーザー目線、エンジニア目線で見ると同社の障害報告やコメントには不安が増してしまう。
- One of the functions of public writeups is to give customers confidence in the organization’s ability to deal with future incidents. This section had the opposite effect, it filled me with dread. It communicates to me that the organization is not interested in understanding how actual work is done.
Building an SRE Team? How to Hire, Assess, & Manage SREs
I like how this article covers the different roles that SREs play.
Emily Arnott — Blameless
- 組織内の SRE チームの役割と責任、およびその構築を開始する方法を以下の3つのポイントに沿って、各ポイントを細分化しながら解説している。
- What do site reliability engineers do?
- How do you build a site reliability engineering team?
- Building SRE teams with Blameless
The Advanced Principles of Chaos Engineering
The principles covered in this article are:
・ Build a hypothesis around steady-state behavior
・Vary real-world events
・Run experiments in production
・Automate experiments to run continuously
・Minimize blast radius
Casey Rosenthal — Verica
- 上記のPrincileや、他の業界にも長年の間暗黙的に存在してきた形式を「カオスエンジニアリング」と明示的に名付けたことの意義、今後などについて解説している。
Why do config changes keep coming up in major incidents?
This post is full of thought-provoking questions on the nature of configuration changes and incidents.
Lorin Hochstein
- 上記のEditorのコメントとタイトルにある通り、構成変更の性質とインシデントについて考察している。
Outages
- IBM Cloud
- Klarna
Klarna showed users information related to other users, as detailed in this followup post.
上記各社の障害情報
KubeWeekly #264 June 4th, 2021←メルマガを受領。(2021/06/06 04:20JST)
The Headlines
Editor’s pick of the highlights from the past week.
#TeamCloudNative goes live with 10 shows on Twitch
We are ecstatic to announce the launch of 10 new community shows on CloudNative.tv starting on June 7th. CNCF launched livestreaming on Twitch at the beginning of the year with Cloud Native Live and interactive shows during KubeCon + CloudNativeCon.
The community has now stepped forward to grow our presence on Twitch and bring many more stories into the spotlight. CloudNative.tv’s vision is to become the definitive interactive media experience for anyone wanting to learn, grow, and collaborate with others in the Cloud Native community from anywhere in the world. CloudNative.tv was created by the community, for the community and anyone can contribute!
The launch includes shows ranging from 101 explainers, to getting started contributing to projects, and highlighting the unique people that make up CNCF’s community of doers. Learn more about CNTV in the blog post.
- 上記の通り、新たな10のコミュニティーのコンテンツが2021/6/7よりTwitch上でスタート。直近のスケジュールとプログラムは以下。詳細は上記の「Learn more」のリンクの記事でご確認を。
- Monday 7th June:
- 23:00 CEST/ 17:00 ET: This Week in Cloud Native
- Tuesday 8th June:
- 18:00 CEST/12:00 ET: 100 Days in Cloud Native with Anaïs Urlichs
- Wednesday 9th June:
- 21.00 CEST/15.00 ET: Cloud Native Classroom with Kat Cosgrove
- Thursday 10th June:
- 22.00 CEST/16.00 ET: Fields Tested with Kaslin Fields
- Friday 11th June:
- 16.00 CEST/10.00 ET: /lgtm with David McKay
- 20.00 CEST/14:00pm ET: Spotlight Live with Dan Pop
- Monday 14th June:
- 19.00 CEST/13.00 ET: Solid State with Tim Banks
- Tuesday 15th June:
- 20.00 CEST/14.00 ET: Cloud Native LatinX with Leonardo Murillo
- Wednesday 16th June:
- 21.00 CEST/15.00 ET: CNCFaceOff with Matt Stratton
- Thursday 17th June:
- 17.00 CEST/11.00 ET: Certs Magic with Saiyam Pathak
- Monday 7th June:
ICYMI: CNCF online programs this week
A weekly summary of CNCF online programs from this week.
How to enable powerful connectivity between Edge sources & Kubernetes backend
Lior Nabat, KubeMQ
- 以下のエッジソースと Kubernetes バックエンド(OpenShift)間の強力な接続を構築する方法を解説している約37分のセッション。
- How to deploy KubeMQ’s lightweight server on the edge
- How to communicate between edge and the Kubernetes backend
- How to protect from edge degraded network stability
- How to achieve high availability on the edge
Have you explore The Kubernetes Aquarium !!!
— Cloud Native Islamabad (@CloudIslamabad) 2021年6月3日
This is a Pod, the basic building block of K8s.
It’s just a box in which we place our containerized app.
Go here and see do every fish dress up properly in a pod:https://t.co/2rHxIxj4ZV
The Technical
Tutorials, tools, and more that take you on a deep dive into the code.
Automating your developer pipeline with APIOps (DevOps + GitOps)
Ross McDonald, Kong
- タイトルに沿って、以下を解説しているチュートリアル。約10分の動画が埋め込まれている。
- Set up an end-to-end automation framework in Kong Konnect.
- Leverage Kong’s declarative configuration tool (decK) to update your API configurations.
- Tie decK into a CI/CD framework for automating updates in the same way you update and deliver code.
- Deploy services with a few simple commands using the tools you already use today.
- Apply policy and govern your services in the same way.
Using finalizers to control deletion
Aaron Alpar, Kasten
- タイトルに沿って以下を解説している。末尾に筆者のプレゼン動画もついているので、理解を深めやすい。
- What properties of a resource govern deletion
- How finalizers and owner references impact object deletion
- How the propagation policy can be used to change the order of deletions
- How deletion works, with examples
Learn how to manage applications across multiple clouds and Kubernetes clusters
Johan Siebens, OpenFaaS
- inlets PROを使用して、機密性の高いKubernetes API Serviceを単一の管理クラスターに安全な方法で取り込む方法を解説している。
An Introduction to PromQL
Chris Ward, Chronosphere
- タイトルに沿って、関連する時系列とメトリクスを返すクエリの作成を開始するための概念の概要、PromQLと他のクエリ言語との違いなどを解説している。
FYI: there is an option now to support his family and education fund for his 10 month old son, I donated and hope others take the time to contribute what they can https://t.co/bXnEgYS8Gh https://t.co/p387fV7fgC pic.twitter.com/LabCDCq8W7
— Chris Aniszczyk (@cra) 2021年6月3日
The Editorial
Articles, announcements, and morethatgive you a high-level overview of challenges and features.
Flux update
Daniel Holbach, Weaveworks
- 「May 2021 update」のページ。Flux v2のリリースから一年経過したこと、機能追加の案内、その他のニュースなどを記載している。
- 次月のJune 2021 updateも出ているので、ご興味のある方はチェックを。
Benchmarking Linkerd and Istio
William Morgan, Linkerd
- タイトル通り、LinkerdとIstioのベンチマークテストの結果と再現方法を共有している。同様の内容を2019年にも実施されているが、2年経過しそれぞれのプロジェクトでアップデートが入っているため、それぞれの最新バージョンで改めて実施している。
Open source’s diversity problem
Matt Asay, InfoWorld
- タイトルに沿って、主に女性のcontributorが少ない点にフォーカスして解説している。
The container incubator
Andrew Leonard, Increment
- CNCFのGM Priyanka Sharma氏、CTO Chris Aniszczyk氏を招いてタイトルの「The container incubator」の観点で、CNCFの役割、IstioのCNCFに寄贈されないことが決まったなどに踏み込んでインタビューしている。
Reminder: Take the CNCF Cloud Native Survey - Part 1 to share your thoughts on cloud, containers, and Kubernetes.
- 先々週案内した「CNCF Cloud Native Survey - Part 1」のリマインダー。
Upcoming CNCF Online Programs
Cloud Native Live
- June 9: Use your favorite programming language to build your dream cloud native platform presented by Matt Stratton, Pulumi - RSVP
On-demand Webinars
June 10: Tackling customer issues in cloud native environments presented by Elinor Swery, Rookout - RSVP
June 10: Cloud native policy enforcement with Open Policy Agent presented by Anders Eknert, Styra - RSVP
June 10: Persist your data In an Ephemeral K8s Ecosystem presented by Eric Zietlow, MayaData - RSVP
Looking for more great curated content? Visit our Online Programs playlist on YouTube.
Learn more about CNCF Online Programs
いかがでしたか?気になる記事や情報はありましたか?
私もまだ内容を咀嚼出来ていないものが多々ありますので、この備忘録兼リンク集を活用しながら理解を深めていきたいと思います。
では、また。
Bye now!!